Cutting costs with Hybrid-Cloud

Operating an infrastructure purely in the public cloud undeniably brings many advantages. Global infrastructure, easy scalability, APIs, and software-defined everything are some of the advantages a Hybrid-Cloud has to offer.

With that being said, every innovation comes with its price, and in the cloud, it is indeed true that ‘the sky is the limit.’ Many companies are starting to realise that while the benefits of the cloud are immense, they don’t necessarily need them for their entire project.
What exactly is Hybrid-Cloud?
Companies can identify and separate server usage into a permanent load (known as base load) and peak demands. Companies will then need to consider whether it’s worth moving the base load back from the cloud to on-premise hardware, saving a significant amount of money and using the cloud only to cover peak performance needs. This is when when we start talking about a hybrid solution: infrastructure spread between the public cloud and one’s own or rented hardware.
Why should businesses consider hybrid cloud in conjunction with AWS?
In practice, there are two main reasons to consider hybrid cloud: location and cost.
Location is usually not so critical as Amazon currently offers eight computing locations (regions) within Europe and more than 25 Edge locations for CDN.
When it comes to cost, the situation becomes quite interesting. AWS and public clouds, in general, offer a plethora of services beyond traditional virtual servers, in the form of serverless and software-as-a-service offerings. Whether it’s databases, storage, emailing, or more complex tools, clouds can practically cover any requirements but come at a significant cost. However, many of these services can be found within on-premise solutions at a lower cost and higher quality. In the case of AWS, these typically include large databases, various queuing services (SQS), and servers to handle base load.
AWS as one of the layers of hybrid architecture.
Overall, it can be said that AWS services can be divided into two categories – true SaaS and services running on Amazon-managed virtual machines. The first category includes SQS, SES, or storage, while the second one includes databases. Many clients who come to us with their AWS solutions rely solely on the fact that AWS services simply do not fail. They try to reduce costs by bypassing fault tolerance. This makes sense in the short term, but in the long run, it leads to significant losses and problems, especially when an AWS service stops functioning. There can be many reasons, but the most common cause is technical hardware failure at Amazon. However, these are also the services that can benefit the most from a hybrid architecture.
For this example we will be looking at an Czech e-shop. The e-shop has several servers for running the application itself, a database, email service (SES), storage, and CDN for content distribution. Most of the time, there is a relatively constant load on the servers, and only occasionally, during marketing campaigns, there is a need to cover peak performance demands. At the same time, all components need to be fault-tolerant, which dramatically increases the cost, especially for databases. The situation can then look like the diagram below.
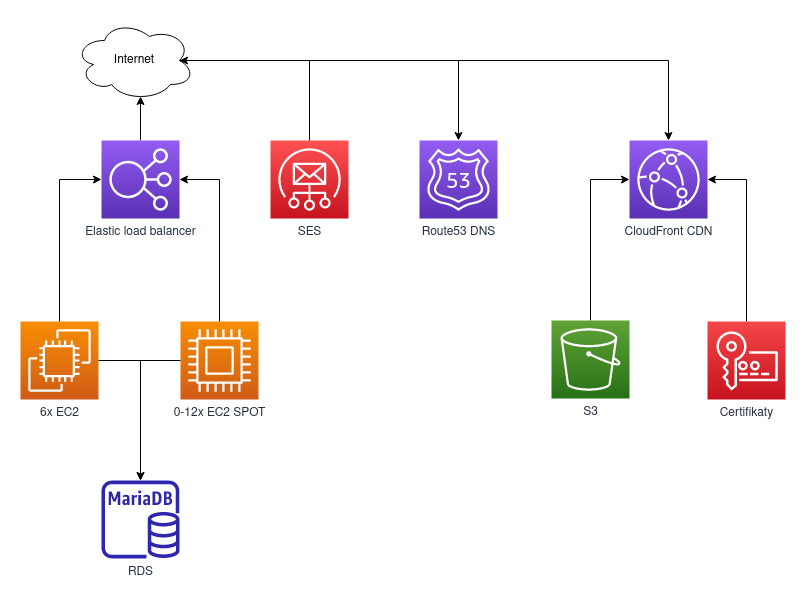
In principle, there is nothing wrong with this setup – except for the single-node RDS, which, in the event of a failure, causes the entire application to crash. Thanks to CloudFront CDN, data reaches customers quickly, dynamically scaled instances cover peak loads, and SES takes care of emailing. For a larger e-shop with approximately 300 GB of data in the database and half a million emails sent monthly, we are talking about a cost of around $3000 per month just for the infrastructure. Don’t believe it? Just take a look at the below calculator.
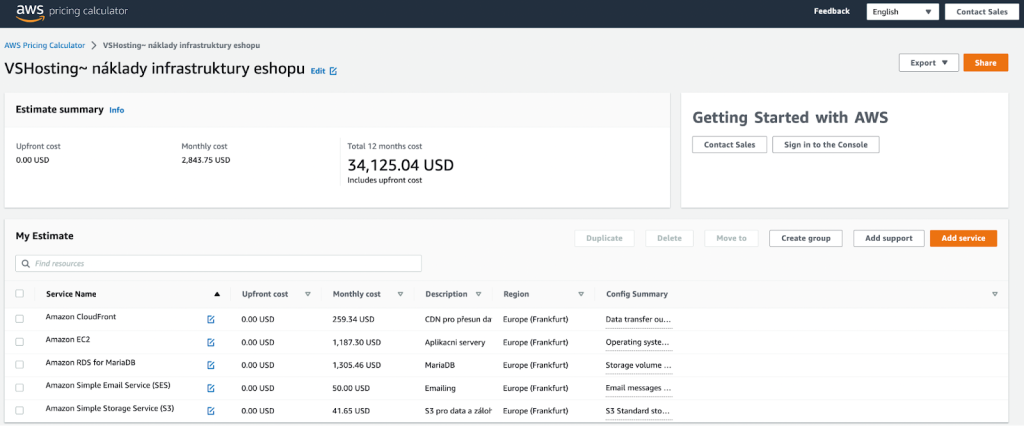
If we wanted to ensure high availability for RDS, the cost would be even higher. Additionally, we need to factor in the time of the people managing the system (even if it’s just developing IaC scripts and monitoring logs), easily exceeding costs well over 250,000 CZK monthly (approximately the price of a lightly used Skoda Fabia car).
Now, let’s see the savings we can achieve by moving some services from AWS to dedicated hardware. The foundation will be a 3-node private cloud on the Proxmox platform. We will move practically everything essential for the e-shop’s operation to this cluster – a database in a master-master setup for fault tolerance, S3 storage, and virtual servers. Due to the placement in the vshosting data center, we can eliminate CDN. In AWS, only the SES email service, DNS Route53, and potential EC2 servers for handling peak traffic, if needed, will remain.
For such a hybrid solution, you will pay around 120,000 CZK monthly (including AWS hardware and AWS management). By implementing a hybrid cloud approach, you reduce costs by more than 50% compared to running purely in AWS. For this price, you not only get a better technical solution but also 24/7 monitoring, management by our experienced administrators, and backups to a geographically separate location.
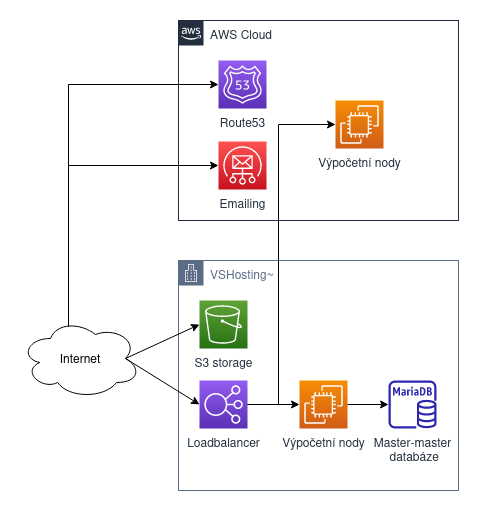
Impressive right?
Are you interested in a hybrid solution and want to know how you could save on costs? Email us at consultation@vshosting.co.uk