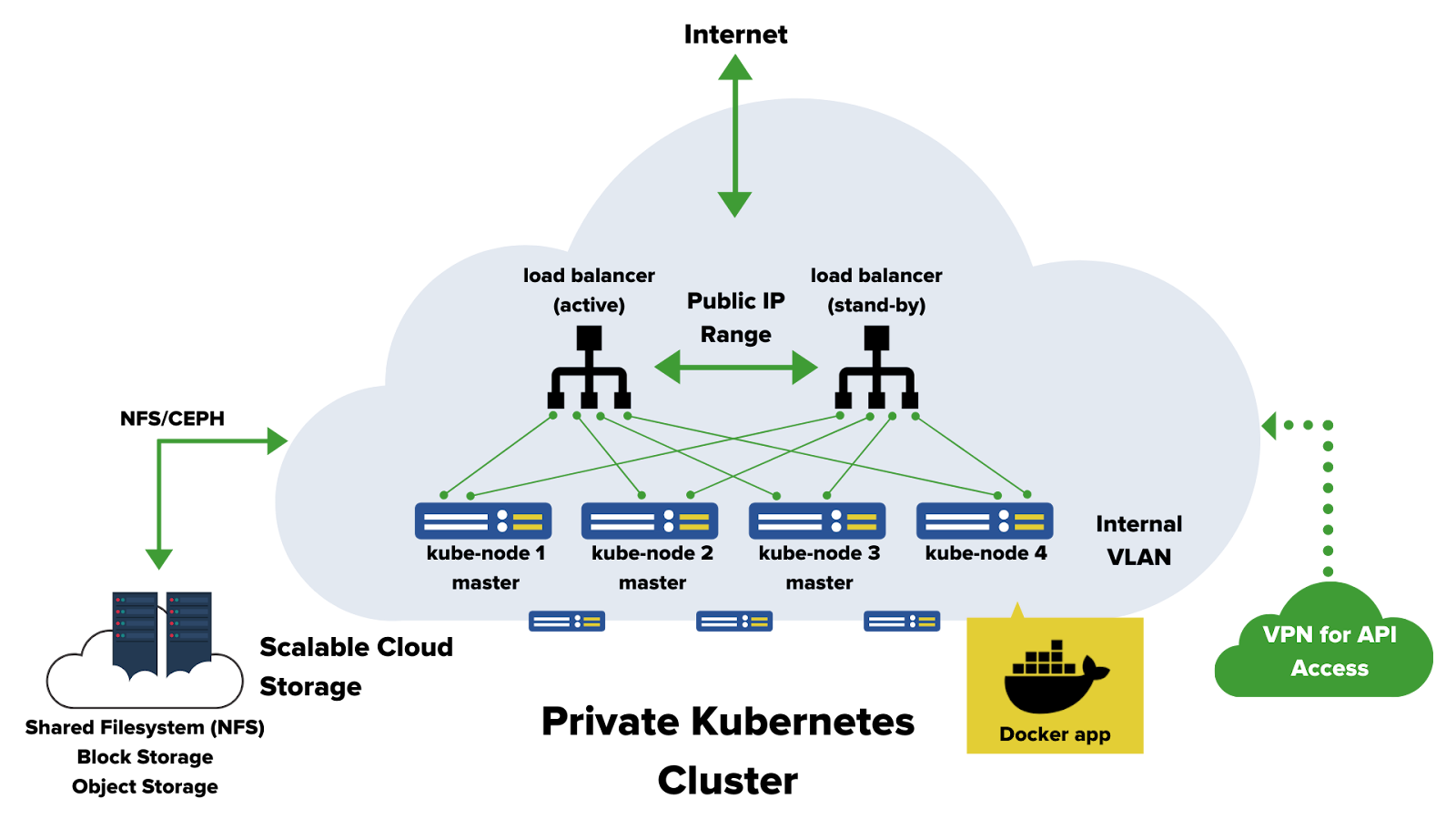
Advantages of Kubernetes from vshosting compared to traditional cloud providers

What sets the Platform for Kubernetes service from vhosting~ apart from similar solutions by Amazon, Google or Microsoft? There is a surprising amount of differences.

What sets the Platform for Kubernetes service from vhosting~ apart from similar solutions by Amazon, Google or Microsoft? There is a surprising amount of differences.
Kubernetes services development
Clients often ask us how our new Platform for Kubernetes service differs from similar products by Amazon, Google or Microsoft, for example. There are in fact a great many differences so we decided to dig into the details in this article.
Individual infrastructure design
The majority of traditional cloud providers offer an infrastructure platform, but the design and individual creation of the infrastructure is left to the client – or rather to their developers. The overwhelming majority of developers will of course tell you that they’d rather deal with development than read a 196-page guide to using Amazon EKS. Furthermore, unlike most manuals, you really need to read this one since setting up Kubernetes on Amazon isn’t very intuitive at all.
At vshosting~ we know how frustrating this is for most companies. The development team should be able to concentrate on development and not waste time on something that they’re not specialized in. Therefore, we make sure that unlike traditional cloud services, our Kubernetes solution is tailor-made for each client. With us, you can skip the complex task of choosing from predefined packages, reading overly long manuals, and having to work out which type of infrastructure best meets your needs. We will design Kubernetes infrastructure exactly according to the needs of your application, including load balancing, networking, storage and other essentials.
In addition, we would love to help you analyze your application before switching to Kubernetes, if you don’t already use it. Based on your requirements we’ll recommend you a selection of the most suitable technologies (consultation is included in the price!), so that everything runs as it should and any subsequent scaling is as straightforward as possible.
In terms of scaling, with Zerops it’s simple. Again there is no choosing from performance packages etc. at vhosting~ you simply scale according to your current needs, no hassle. We also offer the option of fine scaling for only the required resources. Does your application need more RAM or disk space because of customer growth? No problem.
After we create a customized infrastructure design, we’ll carry out the individual installation and set up of Kubernetes and load balancers before putting it into live operation. Just for some perspective, with Google, Amazon or Microsoft, all of this would be on your shoulders. At vshosting~ we carefully fine-tine everything in consultation with you. Once launched, Kubernetes will run on our cloud or on the highest quality hardware in our own data center, ServerPark.
The option of combining physical servers and the cloud
Another benefit of Kubernetes from vshosting~ is the option of combining physical servers with the cloud – other Kubernetes providers do not allow this at all. With this option you can start testing Kubernetes on a lower performance Virtual Machine and only then transfer the project into production by adding physical servers (all at runtime) with the possibility of maintaining the existing VMs for development.
For comparison: Google will for example offer you either the option of on-prem Google Kubernetes Engine or a cloud variant, but you have to choose one or the other. What’s more, you have to manage the on-prem variant “off your own back”. You won’t find the option of combining physical servers with the cloud with Amazon or Microsoft.
You save up to 50% compared to global Kubernetes providers. Take a look at how we compare.
With us you can combine physical servers with the cloud as you see fit and we’ll also take care of administration – leaving you to focus on development. We’ll oversee the management of the operating systems for all Kubernetes nodes and load balancers and we’ll provide regular upgrades of operating systems, kernels etc. (and even an upgrade of Kubernetes, if agreed).
High level of SLA and senior support 24/7
One of the most important criteria in choosing a good Kubernetes platform is its availability. You might be surprised to learn that neither Microsoft AKS nor Google GEK provide a SLA (financially-backed service level agreement) and only claim to “strive to ensure at least 99.5% availability”.
Although Amazon talk about a 99.9% SLA, when you look at their credit return conditions, in reality it’s only a guarantee of 95% availability – since Amazon only return 100% of credit below this level of availability, If availability drops only slightly below 99.9%, they only return 10% of credit.
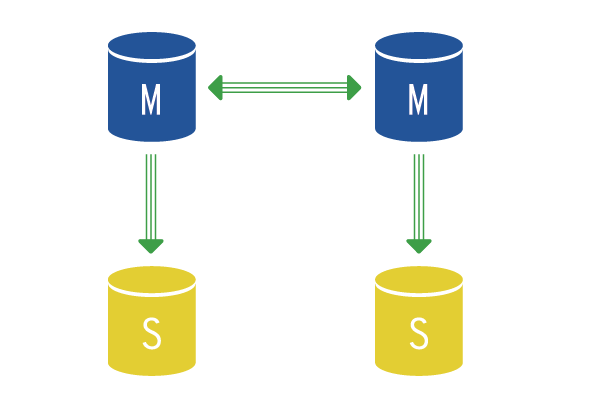
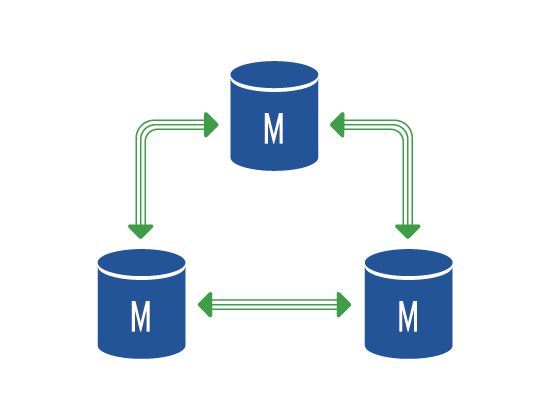
At vshosting~ we contractually guarantee 99.97% availability, that is to say more than Amazon’s somewhat theoretical SLA and significantly more than the 99.5% not guaranteed by Microsoft and Google. In reality, availability with vshosting~ is more like 99.99%. In addition., our Managed Kubernetes solution works in high-availability cluster mode which means that if one of the servers or part of the cloud malfunctions the whole solution immediately starts on a reserve server or on another part of the cloud.
We also guarantee high-speed connectivity and unlimited data flows to the whole world. In addition we ensure dedicated Internet bandwidth for every client. Our network has capacity up to 1 Tbps and each route is backed up many times over.
Thanks to the high-availability cluster regime, high network capability, and back up connection, the Kubernetes solution from vshosting~ is particularly resistant to outages of any part of the cluster. Furthermore, our experienced team will continuously monitor your solution and quickly identify any issues that emerge before they can have an effect on the end user. We also have robust AntiDDoS protection which effectively defends the entire cluster against cyber attacks.
Debugging and monitoring of the entire infrastructure
Unlike traditional cloud providers, at vshosting~ our team of senior administrators and technicians monitor your solution continuously 24 hours a day directly from our data center and will react to any problems which may arise within 60 seconds – even on Saturday at 2am. These experts continuously monitor dozens of parameters relating to the entire solution (hardware, load balancers, Kubernetes) and as a result are able to prevent most issues before they become a problem. In addition, we guarantee to repair or replace a malfunctioning server within 60 minutes.
To keep things as simple as possible, we’ll provide you with just one service contact for all your services- whether it’s about Kubernetes itself, its administration or anything to do with infrastructure. We’ll take care of routine maintenance and complex debugging. Included in the Platform for Kubernetes price we also offer consultation regarding specific Dockerfile formats (3 hours a month).