

Premium Database Backup with Point-In-Time Recovery: MariaDB and PostgreSQL

Never lose database data again with this revolutionary approach.

Imagine you’re in the middle of the peak season, marketing campaigns are in full swing and orders are pouring in. Sounds nice, doesn’t it? Unless the database suddenly stops working that is. Perhaps an inattentive colleague accidentally deletes it. Or maybe the disk array fails – it doesn’t matter in the end, the result is the same. Orders start falling into a black hole. You have no idea what someone bought and for how much, let alone where to send it to them. Of course, you have a database backup, but the file is quite large and it can take several hours to restore.
Now what?
Roll up your sleeves, start pulling the necessary information manually from email logs and other dark corners. And hope that nothing escapes you. But those few hours of recovery will be really long and incredibly expensive. Some orders will certainly be lost and you will be catching up with the hours of database downtime for a few more days.
Standard database backup (and why recovery takes so long)
Standard backup, which most larger e-shoppers are used to, is carried out using the so-called “dump” method, where the entire database is saved as a single file. The file contains sequences of commands that can be edited as needed. This method is very simple to implement. Another advantage is that the backup can be performed directly on the server on which the database is running.
However, a significant disadvantage of the dump is the time needed to restore the database from such a backup. This applies especially to large databases. As each command must be reloaded separately from the saved file into the database, the whole process can take several hours. At the same time, you can only restore the data that was contained in the last dump – you will lose the latest entries in the database that have not yet been backed up. The result is an unpleasant scenario described in the introduction – a lot of manual work and lost sales.
Want to dive deeper into tailored backup solutions? Visit our detailed page to learn how we can help protect your business.
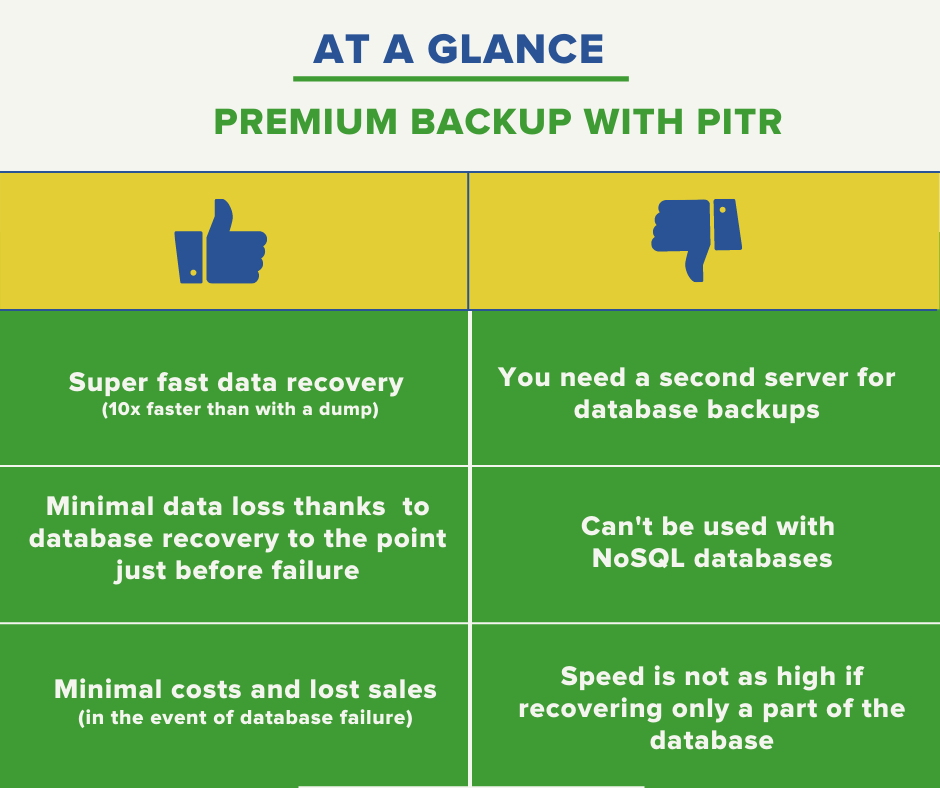
Premium backup with Point-in-time recovery
In order for our clients to avoid similar problems, we offer them premium database backups. This service allows for very fast recovery of databases, to the state just before the moment of failure. We achieve this by combining snapshot backups with binary log replication.
How does it work exactly?
We create an asynchronous replica from the primary database to the backup server. On this backup server, we make a backup using a snapshot. In parallel, we continuously copy binary logs to the backup server, which record all changes in the primary database. In the event of an accident, the logs will help us determine exactly when the problem occurred. At the same time, thanks to them, we have records of operations that immediately preceded the accident and are not backed up by a snapshot.
By combining these two methods, we can – in case of failure – quickly restore the database to its original state (so-called Point-in-time recovery, recovery to a point in time).
First, we restore the latest backup snapshot and copy it to the primary server from the backup server. Subsequently, for binary logs, we identify the place where the destructive operation took place and use them to restore the most recent data.
The speed of the whole process can be as much as 10 times higher than recovery from a dump. It is limited only by the write speed to the disk and the network connection. With a database of around 100 GB, the length of the entire process will be in the order of dozens of minutes.
What is needed for implementation?
Unlike the classic dump backup, which you can perform directly on the primary server, you need a backup server for the premium option. This server should have similar performance as the production server. The size of the storage is also important: we recommend about twice the volume of the disk with the primary database. This capacity should allow snapshots to be backed up for at least the last 48 hours (if you opt for hourly backups).
We will be happy to recommend the ideal storage volume for your database – book a free consultation at consultation@vshosting.eu – it depends on the frequency of backups, the number of changes in your database, and other factors.
Premium backup also depends on the choice of database technologies. Due to the use of binary logs, it can only be implemented in relational databases such as MariaDB or PostgreSQL. NoSQL databases do not have a transaction log and are therefore not compatible with this method.
Another condition is a more conservative database setup on the backup server. The repository must always be consistent in order to take snapshots using ZFS. Upgrades that prioritize database performance over consistency cannot be used on the backup server. Therefore, it is necessary to choose a faster storage option than on the primary server, where a higher performance setting that reduces consistency is feasible.
Is the premium database backup for you?
If you can’t afford to lose any data in your business, let alone run for hours without a database, our premium backup with Point-in-time recovery is right for you. An example of a project that will benefit the most from this service is an online store with large databases, which would cost thousands of euros. In this case, an investment in the backup server needed for premium backup will pay off very quickly.
Conversely, if you have a smaller database with just a few changes per hour, you’re probably perfectly fine opting for a standard dump backup.
If you have any questions, we’ll be happy to advise you free of charge: consultation@vshosting.eu.


